VIII – Le web ou World Wide Web
Né en 1989, pour les besoins internes du CERN (Centre Européen de Recherche Nucléaire), le web, WWW ou World Wide Web est aujourd'hui le service le plus connu et le plus utilisé d'Internet. Son succès est dû à plusieurs facteurs : l'apparente simplicité des logiciels de navigation, la présentation conviviale et multimédia des documents mis à disposition des internautes et la puissance du système en lui-même. Aujourd'hui, le Web est la vitrine de l'Internet. Il donne accès à un nombre incalculable de documents sur des thèmes les plus variés, et ce, en toute convivialité. Avant d'entrer dans le vif du sujet, abordons quelques notions techniques de base.
o Aspects techniques du web
Le web est un ensemble de serveurs proposant des documents accessibles via un protocole appelé HTTP pour HyperText Transfer Protocol. Un serveur web est tout simplement un logiciel qui reconnaît ce protocole. Les programmes qui permettent de se connecter à ce type de serveurs, en utilisant donc HTTP, s'appellent des navigateurs web. Netscape Navigator est le plus connu de ces programmes (nous en reparlerons plus bas).
Un serveur web met à disposition des utilisateurs de navigateurs des documents de tous types : textes classiques, images, sons, animations, applications Java ou même n'importe quel fichier binaire. Un navigateur est capable d'afficher un certain nombre de ces types de fichiers, en particulier tout ce qui est texte, image et son. Cependant, les documents qui structurent les serveurs web sont un peu particuliers : ils sont appelés pages HTML. Le HTML (HyperText Markup Language) est un langage qui permet de composer un document, visualisé via un navigateur web, et ayant une certaine mise en page. On peut changer la couleur du texte, sa taille, ses attributs, insérer des images, animations, etc.
En plus de ces attributs de mise en forme, le HTML autorise l'incorporation dans une page de ce qu'on appelle des liens hypertextes (ou links en anglais). Ce sont ces liens qui permettent d'accéder aux différents documents (qui peuvent être d'autres pages HTML mais également tout type de fichier) proposés par un serveur web. Là où la technologie montre tout son intérêt, c'est qu'un lien peut désigner en réalité n'importe quel document mis à disposition par n'importe quel serveur web accessible de par le monde. On dit alors qu'il s'agit de liens externes. Ces derniers créent une sorte de toile où les points d'intersection sont des documents HTML. Voilà pourquoi on parle de web (toile en anglais).
Notez enfin que les adresses DNS des serveurs web sont généralement préfixées par les lettres www pour World Wide Web. Par exemple, le serveur web d'IBM a pour adresse :
www.ibm.com. Comme pour le FTP, notez que ce préfixe n'a rien d'obligatoire. C'est juste une façon de permettre de trouver plus facilement le serveur web d'une société ou organisation donnée.
o Les URL
Nous venons de le dire : un lien, inséré dans une page HTML, peut désigner n'importe quel document (au sens large, c'est-à-dire tout type de fichier) sur n'importe quel serveur. Ce système ne peut fonctionner que si l'on peut trouver un procédé permettant de donner un nom unique à chaque document accessible. Ce procédé a pour nom : URL pour Uniform Resource Locator. Une URL a la forme suivante :
protocole://adresse_serveur:numéro_de_port/chemin…/document
Exemple :
http://www.ibm.com/products/index.html
Remarque : Il existe certaines exceptions concernant la structure d'une URL. Cela concerne notamment les URL permettant de désigner une adresse E-Mail ou un newsgroup. Voici deux exemples illustrant ces particularités :
La première URL permet d'expédier un message électronique à la personne dont l'adresse est indiquée après le "mailto:", tandis que la seconde désigne une conférence. Lorsque l'on "active" ce genre de lien dans un navigateur web (dont nous allons parler davantage dans quelques instants), cela lance le module prenant en charge le service correspondant (respectivement un logiciel de messagerie et un programme de gestion de conférences).
o Navigateurs web
Les logiciels qui permettent de se connecter à des serveurs web s'appellent des navigateurs web (ou browsers en anglais), comme nous l'avons déjà dit. Les deux navigateurs les plus connus sont ceux de Microsoft (Internet Explorer) et de Netscape (Navigator dans la suite Communicator). Il y a quelques années, un logiciel nommé Mosaic était la référence en matière de navigateurs web. Il a été relégué au rang des antiquités depuis l'arrivée de Navigator puis d'Internet Explorer. Ces logiciels permettent non seulement d'accéder à des serveurs web mais aussi à des serveurs FTP, Gopher,…comme nous l'avons vu plus haut lorsque nous parlions des URL. De plus, ils sont livrés avec une série de programmes permettant de lire son courrier, consulter les conférences, créer des pages web…Voyons concrètement à quoi ressemble un document HTML affiché grâce à un navigateur web (figure 1).
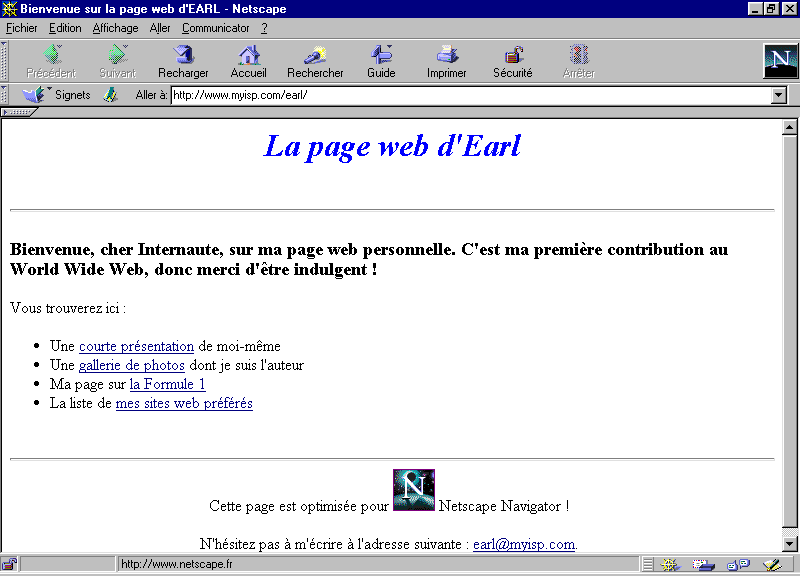
Figure 1 : Exemple de page web
La page ci-dessus a été conçue de façon à faire apparaître les principaux éléments d'une page web, affichée par l'intermédiaire de Netscape Navigator. Nous allons détailler ces éléments un à un.
Tout d'abord, remarquons le titre de la fenêtre, en haut de l'écran : "Bienvenue sur la page web d'EARL - Netscape". Il reprend le titre de la page en cours de visualisation, auquel le nom du logiciel a été ajouté (Netscape donc). On distingue ensuite une barre de menus classique, puis un ensemble d'icônes. Ces dernières donnent accès aux principales fonctions du logiciel, telles que celles que nous allons présenter dans le prochain paragraphe. En dessous de cette barre, on aperçoit l'URL de la page en cours de consultation : http://www.myisp.com/earl/. La partie intérieure de la fenêtre, qui occupe presque les trois quarts de l'écran, constitue la fenêtre de visualisation ou de navigation des documents HTML. C'est dans cette zone que sont affichées les informations proposées par les serveurs web que vous consulterez. Dans l'exemple étudié, on a utilisé plusieurs tailles de texte et employé de la couleur pour le "titre" indiqué en tête de la page HTML.
Les différentes parties du document ont été ici séparées par des barres horizontales. Dans la partie centrale, on a spécifié une liste d'URL permettant d'accéder à différentes pages. Ces URL ou liens sont reconnaissables dans un document HTML par la façon dont ils sont présentés par le navigateur :
En général, avec un peu d'habitude, il n'est pas difficile de repérer un lien, rien qu'en déplaçant le curseur sur les zones susceptibles d'en contenir un et en regardant si le pointeur de souris change de forme. Il suffit alors de cliquer une fois (simple clic) afin d'obtenir le contenu de la page ainsi désignée.
Il est important de noter qu'un lien n'est pas forcément rendu accessible via une portion de texte mise en évidence dans un texte, comme nous l'avons vu ci-dessus. En effet, on peut tout à fait associer un lien à une image entière ou même seulement à une portion d'image. Nous avons d'ailleurs associé un lien, vers la page d'accueil du serveur de la société Netscape, à l'image située en bas de l'écran, représentant le logo de la société (la lettre N). Dans certains cas, lorsqu'une image entière est associée à une URL, cette image est entourée d'un cadre de couleur bleue, comme pour un lien classique sous forme de texte. Mais ce n'est toujours pas une obligation. Nous avons d'autre part illustré ce que nous disions un peu plus haut concernant la barre de statut et les liens, en positionnant le curseur de la souris sur le logo Netscape : on aperçoit bien l'URL du serveur de cette société indiquée dans la dite barre.
Enfin, la dernière ligne de cette page comprend une URL permettant de laisser un message à l'auteur de celle-ci. Cette URL est du type mailto, dont nous avons parlé au paragraphe précédent. Si on clique sur l'adresse E-Mail ainsi spécifiée, le logiciel de messagerie utilisé par défaut s'affiche à l'écran, permettant ainsi d'envoyer un message à la personne correspondante.
Nous allons maintenant aborder les principales fonctions proposées par les logiciels de navigation sur le web.
o Fonctions de base des navigateurs web
Au lancement de votre navigateur web, il se peut qu'une page s'affiche par défaut. Il peut s'agir de la homepage de la société ayant réalisé le logiciel, ou de la page d'accueil de votre fournisseur d'accès Internet. Cette page, dite de démarrage, peut être changée dans les paramètres du logiciel. Il est également possible de lui demander de n'afficher qu'une fenêtre vide lors de son lancement.
La première chose à connaître quand on utilise un navigateur est de savoir comment consulter un serveur dont on dispose de l'URL. En fait, ce n'est pas très compliqué : il suffit de repérer à l'écran une zone de saisie horizontale, marquée URL, Location, Adresse ou encore Net Site, et d'y entrer l'URL en validant via la touche Entrée (RETURN). Cette zone se situe en général dans la partie supérieure de l'écran, entre la zone destinée à l'affichage des documents parcourus (zone inférieure) et la barre de boutons permettant d'accéder aux principales fonctionnalités du logiciels (en haut). Ces principales commandes sont en général les suivantes :
Il existe d'autres commandes, mais elles ont une moins grande importance que celles que nous venons de décrire.
Les signets, favoris, bookmarks et hotlists.
Un navigateur permet d'accéder à de très nombreux sites, ayant chacun une URL précise. Comme il est impossible de se souvenir de toutes ces adresses, on a inventé un système permettant à l'utilisateur de stocker dans un fichier la liste de tous les sites qu'il souhaite pouvoir retrouver ultérieurement. Le fait de stocker la référence d'un site (qui comporte son URL et le titre de la page vers laquelle elle pointe) constitue ce qu'on appelle un signet (Netscape) ou un favori (Microsoft). En anglais, l'ensemble des signets (bookmarks) est parfois appelé une hotlist. Par extension, en Français, on qualifie parfois de bookmark un ensemble de signets (bien que cela soit un abus de langage).
Naviguer sur le web (on dit parfois surfer) entraîne l'utilisateur à parcourir de nombreux documents sur un ou plusieurs sites. Le problème est qu'au bout d'un certain temps, on risque de se perdre quelque peu, ou oubliant d'où l'on vient…Heureusement, pour soulager la mémoire du surfer, les navigateurs possèdent un historique des documents (URL) visualisés depuis un certain nombre de jours (généralement une semaine). Cet historique stocke les URL de tous les documents accédés, ainsi que le titre de chacun d'entre eux. En fait, quand on utilise les commandes de déplacement Suivant et Précédent, on se déplace dans l'historique. Ce dernier est cependant consultable en lui-même, de façon à retrouver précisément un site consulté la veille et qu'on avait oublié de mettre dans son bookmark…Voir la figure ci-dessous.
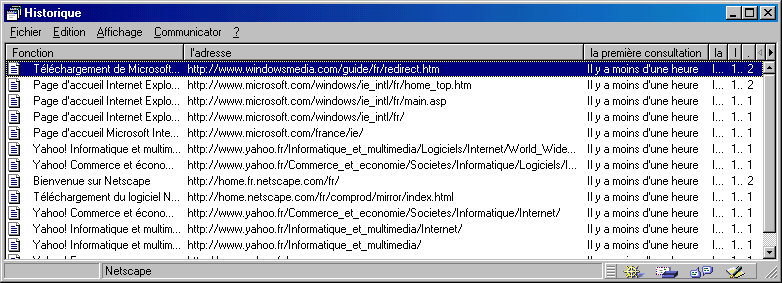
Figure 2 : Historique sous Navigator
o Créer sa page web
Si vous disposez d'un abonnement chez un fournisseur d'accès Internet, il est très probable qu'il vous propose également de créer votre propre page web, hébergée sur un des serveurs web de votre fournisseur. Plusieurs cas peuvent alors se présenter :
Si vous souhaitez réaliser votre propre site, vous pouvez soit apprendre le langage HTML et écrire vos pages avec un simple éditeur de textes, comme le notepad sous Windows (une page HTML est en effet un simple fichier texte, comportant un certain nombre de commandes spécifiques au langage, et ayant .html comme extension) soit utiliser un outil plus puissant doté d'une interface graphique facilitant la composition de vos pages. Certains de ces outils peuvent entièrement masquer le langage à l'utilisateur, permettant ainsi de créer des pages relativement facilement. Par exemple, les dernières versions de Microsoft Word autorisent l'enregistrement d'un document au format HTML, effectuant ainsi une conversion aisée et automatisée. De même, Composer, livré avec la suite logiciel de Netscape, permet de réaliser des pages web relativement simplement. Enfin, il existe des outils intermédiaires qui comprennent un éditeur de texte associé à de nombreuses icônes permettant d'insérer des tags HTML, ainsi que des assistants facilitant par exemple la mise en place d'images et autres éléments multimédia ou animés : musiques, sons, scripts et/ou applets Java (Cf. encadré)…
Pour une présentation un peu plus détaillée du langage HTML, consultez l'annexe B ou procurez-vous un ouvrage spécifique indiqué en référence.
Java, JavaScript and Co.
Nous l'avons vu, une page HTML peut contenir du texte, des images, du sons, etc. A l'origine, aucune interactivité n'était possible entre un document affiché dans un navigateur et l'utilisateur. Par exemple, après avoir terminé la saisie d'un formulaire, il fallait obligatoirement que le serveur intervienne pour valider les données entrées. De plus, les rares animations que l'on rencontrait sur certaines pages se limitaient à l'affichage successif de plusieurs images en un même emplacement, simulant ainsi un semblant d'animation.
Heureusement, un langage de programmation nommé Java, fortement "orienté Internet", apparut en 1995 et donna naissance au concept d'applet (petite application). Une applet est un programme qui s'exécute au cœur d'un navigateur, pouvant ainsi directement dialoguer avec l'utilisateur. Les applets sont téléchargées automatiquement par le logiciel, à partir du site sur lequel elles sont stockées. Aujourd'hui, la majorité des navigateurs disponibles sur les principales plates-formes logicielles et matérielles est compatible Java. Un dernier point important est par ailleurs à signaler : une même applet Java peut s'exécuter sans aucune modification au sein de différents navigateurs, même s'ils ne fonctionnent pas sur le même type de système. C'est une des forces du concept.
Java est reconnu par les navigateurs de Netscape et Microsoft.
Un autre langage est également utilisé pour rendre une page web plus interactive : il s'agit de Javascript, inventé par Netscape. Inspiré de Java, ce n'est qu'un langage de script, utilisable uniquement dans un document HTML (alors que Java est un langage de programmation à part entière). VBScript, de Microsoft, est le concurrent de Javascript. Ce dernier est cependant reconnu par un plus grand nombre de navigateurs, y compris Internet Explorer.
Enfin, citons une technologie nommée ActiveX, inventée par Microsoft, mais qui n'a pour le moment pas connu le succès rencontré par Java.
o Pages dynamiques et frames
Dans ce paragraphe, nous allons aborder deux notions à connaître concernant les serveurs web.
Nous n'avons parlé jusqu'à maintenant que de pages web statiques : à chaque fois qu'un navigateur demande une page de ce type, il obtient systématiquement le même affichage (sauf si la page a été modifiée depuis la dernière consultation, bien sûr). Si de telles pages sont parfaites pour présenter des informations ou autres documents, il est parfois nécessaire de proposer des services interactifs, comme par exemple un système de recherche de documents basé sur la saisie d'un ou plusieurs mots clés (on parle de moteur de recherche).
Ce type d'application ne peut être réalisé à l'aide d'une applet Java puisque celle-ci s'exécute en local, au sein du navigateur. Il faut donc un programme, exécuté sur le serveur web considéré, et ayant la possibilité de dialoguer avec l'utilisateur via son navigateur web. Ce type de programme porte le nom de CGI (Common Gateway Interface). On y accède généralement via un formulaire de saisie. Voici un exemple de formulaire permettant à l'utilisateur de saisir ses coordonnées. Les données ainsi obtenues sont mémorisées sur le serveur grâce à un programme CGI.
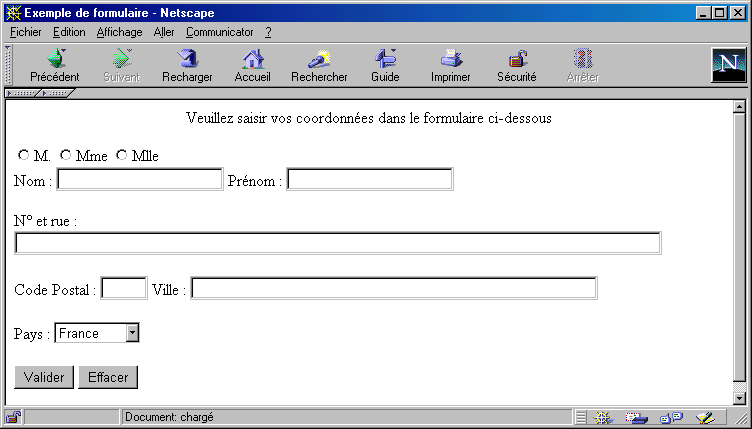
Figure 3 : Exemple de formulaire
On remarque ici plusieurs types d'éléments : trois boutons radio (M., Mme, Mlle), cinq zones de saisie libre, où l'on peut entrer un texte quelconque et enfin une liste déroulante permettant de spécifier le pays. Enfin, un bouton permet de réinitialiser le formulaire, tandis qu'un deuxième permet de le valider et de l'envoyer au serveur.
Deuxième notion fréquemment rencontrée : les frames ou cadres. Avant leur invention, les documents HTML étaient systématiquement constitués d'une seule et même page. Les frames permettent de diviser la fenêtre d'un navigateur et plusieurs zones dont le contenu peu évoluer indépendamment. Ce procédé permet par exemple de garder en permanence le sommaire d'un serveur consulté, dans une frame située sur la gauche de l'écran, évitant ainsi de devoir reculer de plusieurs pages dans l'historique avant d'afficher à nouveau le sommaire du serveur considéré.
o Accéder à un serveur FTP à l'aide d'un navigateur
Comme nous l'avons dit un peu plus haut, il est tout à fait possible d'accéder à un serveur FTP en utilisant un navigateur web. Pour ce faire, on indique l'adresse du serveur sous forme d'URL préfixée par ftp://. Ensuite, il ne reste plus qu'à cliquer sur les répertoires ainsi affichés pour en voir le contenu ou sur les noms de fichiers pour les récupérer. Il est par ailleurs tout à fait possible de mettre un signet sur un répertoire précis d'un site FTP, comme s'il s'agissait d'une page web. Dans ce cas, puisqu'il n'y a pas de "titre" pour le répertoire, c'est l'URL elle-même qui apparaît dans la liste des signets.
Exemple du serveur FTP de Netscape (ftp://ftp.netscape.com) :
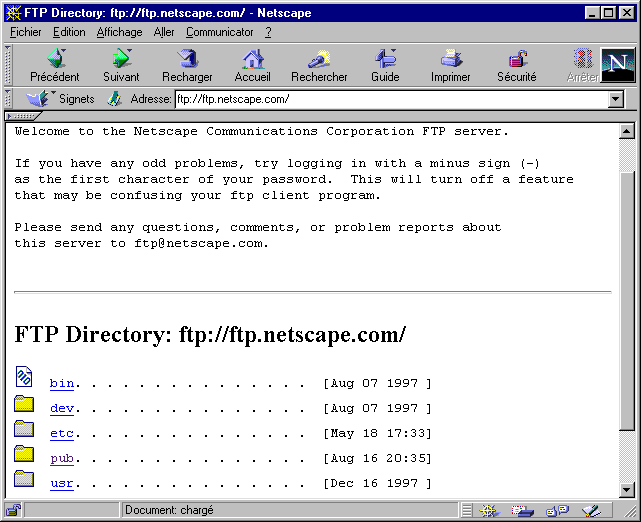
Figure 4 : Accès à un serveur FTP via un navigateur
Dans cet exemple, on reconnaît sans difficulté une liste de répertoires, dont le nom est précédé d'une icône en forme de dossier. Pour se rendre dans un répertoire afin d'en connaître le contenu, il suffit de cliquer sur son nom. Un simple clic permet également de récupérer un fichier.
o Les proxies
Il y a beaucoup de chance que vous entendiez parler un jour ou l'autre de proxies. C'est pourquoi nous allons en dire quelques mots ici. Un proxy est un serveur qui a généralement deux rôles, qui peuvent être confondus :
Tous les navigateurs permettent aujourd'hui d'utiliser des proxies. Dans certains cas, un proxy peut simultanément servir de passerelle (1er cas ci-dessus) et de cache (2ème cas).
Avant de continuer notre exploration du Net, disons quelques mots sur la technologie Push.
o Le Push
La technologie Push est apparue en 1997 avec l'arrivée des versions 4 des navigateurs de Netscape et de Microsoft. Le Push propose une nouvelle façon de faire parvenir des documents HTML (ou autres) à un certain nombre de clients s'étant abonnés à un canal Push proposé par un serveur.
Dans le cas du web, c'est le navigateur qui demande l'envoi d'un document. Le serveur ne peut que répondre à la requête du client. Le problème est que lorsque le document est mis à jour, le client n'en est pas informé tant qu'il ne va pas consulter à nouveau le serveur proposant le document considéré.
Avec le Push, c'est l'inverse : le client "s'abonne" à un "canal" proposé sur un serveur. A chaque fois qu'un document est modifié, celui-ci est automatiquement envoyé aux clients abonnés. Mais ce système n'est pas uniquement limité à des documents : il peut permettre également de diffuser automatiquement les mises à jour de certains logiciels, via le réseau. La technologie Push est encore jeune mais semble très prometteuse, notamment pour les entreprises.